最近、サンプルを作ったのでメモ的に残しておきます。
音声ファイルにあわせて口パクさせていますが、音声を分析してリップシンクをしているわけではないので、適当に口パクさせてそれっぽくしています。
あまりWebで情報が見つからなかったので参考までに。(ステレオミキサー使ったものなら結構ありましたが、使いたくなかったので・・・)
公式のドキュメントはこちら
GitHub

GitHub – DenchiSoft/VTubeStudio: VTube Studio API Development Page
VTube Studio API Development Page. Contribute to DenchiSoft/VTubeStudio development by creating an account on GitHub.
import asyncio
import json
import websockets
import random
import pygame
import os
AUDIO_FOLDER = "audio/Word2Motion"
TOKEN_FILE = "token.txt"
PARAMETER_ID = "MouthOpen"
VTS_URI = "ws://localhost:8001"
async def send_mouth_open(ws, value, request_id):
await ws.send(json.dumps({
"apiName": "VTubeStudioPublicAPI",
"apiVersion": "1.0",
"requestID": request_id,
"messageType": "InjectParameterDataRequest",
"data": {
"faceFound": False,
"mode": "set",
"parameterValues": [
{
"id": PARAMETER_ID,
"value": value
}
]
}
}))
async def get_or_create_token(ws):
if os.path.exists(TOKEN_FILE):
with open(TOKEN_FILE, "r", encoding="utf-8") as f:
return f.read().strip()
await ws.send(json.dumps({
"apiName": "VTubeStudioPublicAPI",
"apiVersion": "1.0",
"messageType": "AuthenticationTokenRequest",
"requestID": "get-token",
"data": {
"pluginName": "InjectTester",
"pluginDeveloper": "You"
}
}))
token_response = json.loads(await ws.recv())
token = token_response["data"]["authenticationToken"]
with open(TOKEN_FILE, "w", encoding="utf-8") as f:
f.write(token)
return token
async def authenticate(ws):
token = await get_or_create_token(ws)
await ws.send(json.dumps({
"apiName": "VTubeStudioPublicAPI",
"apiVersion": "1.0",
"messageType": "AuthenticationRequest",
"requestID": "auth",
"data": {
"pluginName": "InjectTester",
"pluginDeveloper": "You",
"authenticationToken": token
}
}))
resp = await ws.recv()
print("✅ 認証成功:", resp)
async def keep_alive(ws):
while True:
try:
await ws.ping()
await asyncio.sleep(5) # pingを5秒おきに送信して切断防止
except Exception as e:
print(f"⚠️ KeepAlive失敗: {e}")
break
async def play_with_mouth_sync(file_path, ws):
print(f"🎵 再生開始: {file_path}")
pygame.mixer.music.load(file_path)
pygame.mixer.music.play()
while pygame.mixer.music.get_busy():
open_val = round(random.uniform(0.2, 1.0), 2)
await send_mouth_open(ws, open_val, "inject-open")
await asyncio.sleep(random.uniform(0.05, 0.15))
await send_mouth_open(ws, 0.0, "inject-close")
await asyncio.sleep(random.uniform(0.05, 0.15))
print(f"🛑 再生終了: {file_path}")
async def run_all_audio():
pygame.mixer.init()
files = sorted([
os.path.join(AUDIO_FOLDER, f)
for f in os.listdir(AUDIO_FOLDER)
if f.lower().endswith(".wav")
])
async with websockets.connect(VTS_URI, ping_interval=None) as ws:
await authenticate(ws)
# KeepAliveをバックグラウンドで走らせる
keepalive_task = asyncio.create_task(keep_alive(ws))
for file_path in files:
await play_with_mouth_sync(file_path, ws)
await asyncio.sleep(0.3)
keepalive_task.cancel()
asyncio.run(run_all_audio())
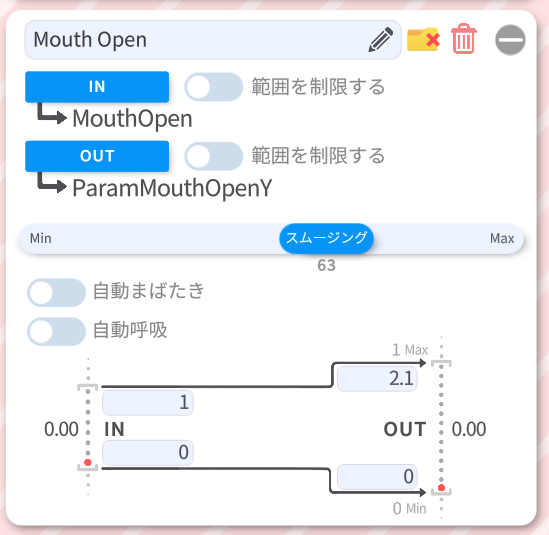
最低限このあたりの設定はVtube Studio側で必要です。
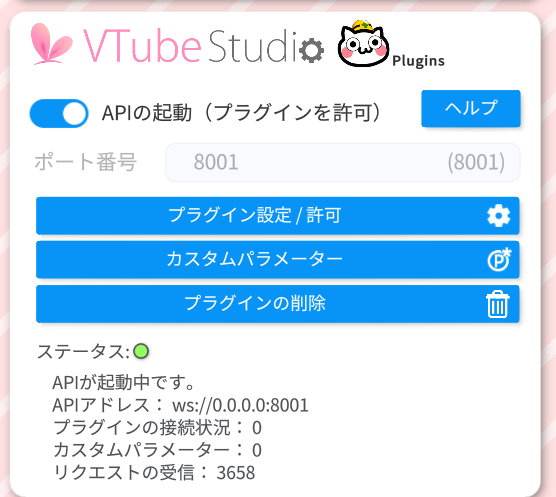
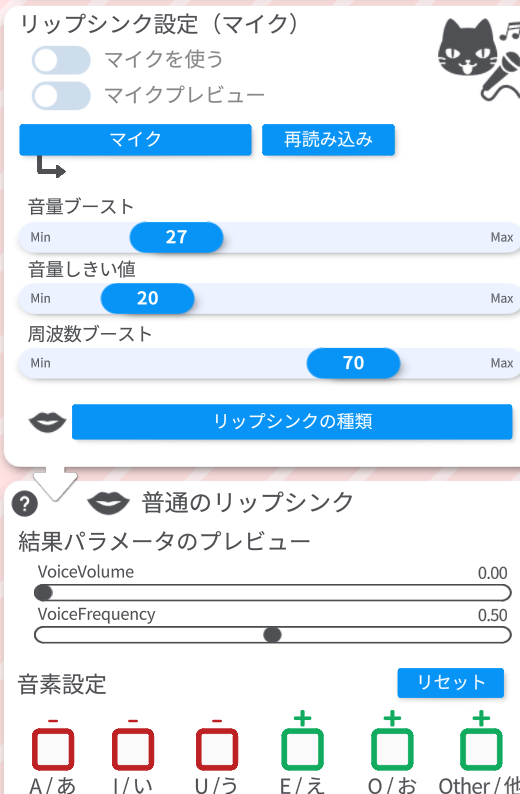
スムージングを大きくすることで、口パクの動きがスムーズになります。
目次
機能概要
- 指定フォルダ内の音声(WAV)を順番に再生
- 再生中に口の開閉をランダムな値で送信
- VTube StudioとのWebSocket認証とトークンの永続化
- WebSocketが切断されないように定期的にping送信
ファイル構成
audio/Word2Motion/:音声ファイルフォルダ(WAV形式)token.txt:VTS APIの認証トークン保存用ファイル
主な処理の流れ
1. VTSとの接続と認証
async with websockets.connect(VTS_URI, ping_interval=None) as ws:
await authenticate(ws)
認証トークンがなければ生成・保存し、次回以降は再利用することで毎回の「許可」操作を不要化しています。
音声再生と口パク制御
while pygame.mixer.music.get_busy():
open_val = round(random.uniform(0.2, 1.0), 2)
await send_mouth_open(ws, open_val, "inject-open")
await asyncio.sleep(...)
pygame.mixer で音声を再生
再生中に MouthOpen パラメータへランダム値(0.2〜1.0)を送信
開→閉を繰り返して自然な口パクを表現
接続維持の工夫(KeepAlive)
async def keep_alive(ws):
await ws.ping()
WebSocketの自動切断を防ぐために、バックグラウンドで5秒ごとにpingを送信しています。
まとめ
このスクリプトを使えば、VTube Studioと連携して任意の音声再生中に自動で口パクを再現できます。簡易的なライブ演出や音声ボットのアバター化などに活用できます。