
今回紹介するテーマは「スクレイピング>自動ログイン>テキスト情報の収集」です。
スクレイピングとは、Webサイトで公開されている情報から特定の情報を抽出する技術のとこです。 スクレイピングを利用することで、APIが提供されていない情報を取得したり、それを利用して日々の 情報収集を自動化することができます。
スクレイピングをできるようになると、データ収集する手間や時間を削減することができるので、 ぜひ習得してみましょう。
前準備
前準備するリスト
- GoogleChrome…この記事では、Chromeを利用した方法を紹介します。
- ChromeDriver…PythonからChromeを操作するために使用します。
- selenium…スクレイプングをするためのPythonライブラリ
Google Chromeのインストール
この記事では、GoogleChromeを利用した方法を紹介します。 インストールしていない方は、以下のリンクからダウンロードすることができます。
インストールしていない方は、以下のリンクからダウンロードすることができます。

ChromeDriverのインストール
自分のクロームのバージョンを確認します。 以下のPathをchromeのアドレス欄にコピーしてバージョン情報を確認できます。
chrome://settings/help 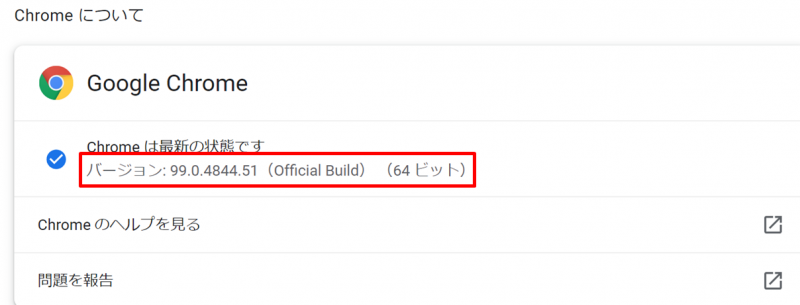
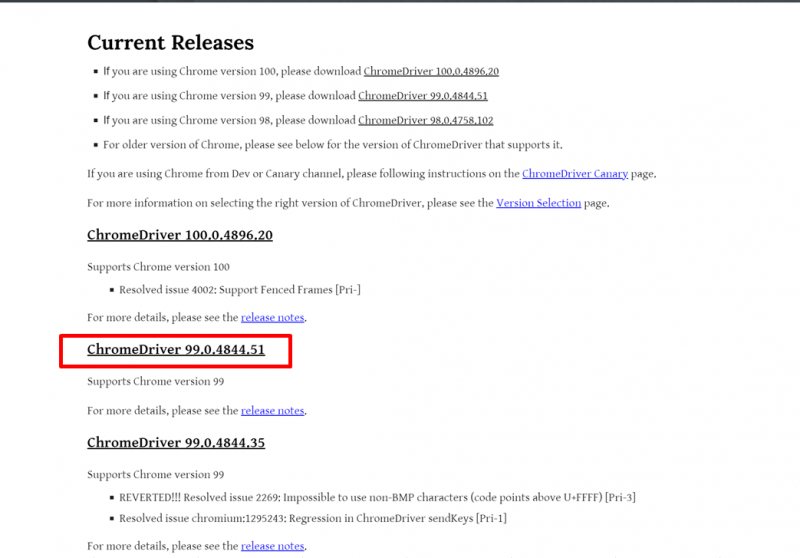
「ChromeDriver」は以下のリンクから取得できます。 新しいバージョンをクリックします。

にアクセスして、クロームのバージョンを確認し、自分のバージョンのChromeDirverをダウンロードします。
利用するOSにあったものをクリックしてダウンロードします。 今回は、windowsを例に説明します。
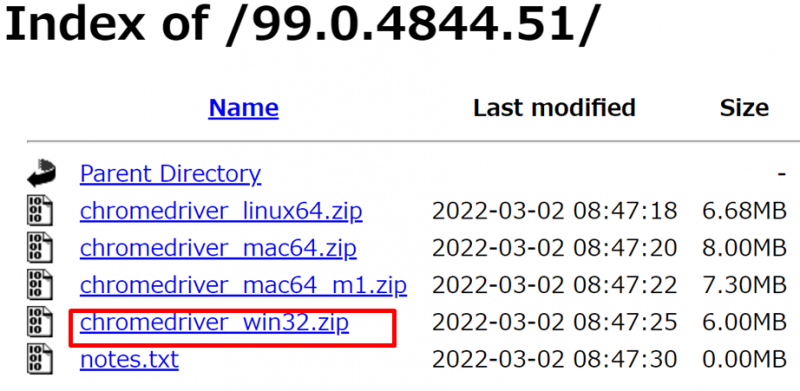
ダウンロードできたらそのファイルを解凍します。 windowsファイルの場合は、 「chromedriver.exe」がでてきますので、これを今回は
C:\chromedriver\chromedriver.exe
に保存します。あとでプログラムからこのファイルへのPATHを設定します。
これで、ChromeDriverの準備は完了です。
seleniumをpipする
「selenium」を「PIP」でインストールします。
pip install selenium上記でうまく入らない場合は、以下で「PIP」をアップデートしてから、再度試してみて下さい。
pip install --upgrade pipコードからChromeを起動してみよう
Chromeを起動させる簡単なプログラムを書いて前準備ができているか確認します。
import selenium
from selenium import webdriver
#ChromeDriverのPATHを設定する
chromeDriverPath = "C:\chromedriver\chromedriver.exe"
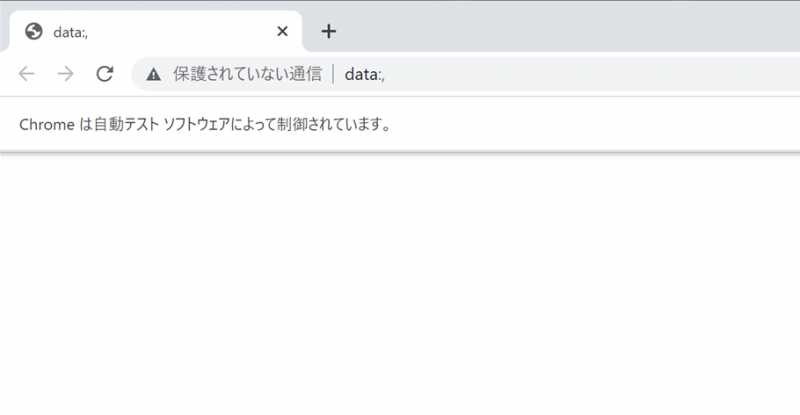
driver = webdriver.Chrome(executable_path=chromeDriverPath)成功すると「Chromeは自動テスト ソフトウェアによって制御されています。」というメッセージで ブラウザが起動します。
ChromeDriverの保存位置を設定しています。この場所以外に保存している場合は、自分のPathに書き換えて下さい。
chromeDriverPath = "C:\chromedriver\chromedriver.exe"操作するオブジェクトの取得と、ブラウザの起動を行っています。
driver = webdriver.Chrome(executable_path=chromeDriverPath)自動でログインしてみよう
今回は例として、yahooにログインしてみます。
Chromeでサイトの要素を取得する
スクレイピングを行うためには、ログインページの要素を先に取得する必要があるので、その方法を説明します。
まずはChromeでyahooのログイン画面にアクセスします。
※既にログインしている方は、一度ログアウトして下さい。
「F12」を押して、HTML等の調査用画面を出します。

次に、調査用画面左上にある矢印ボタンをクリックします。
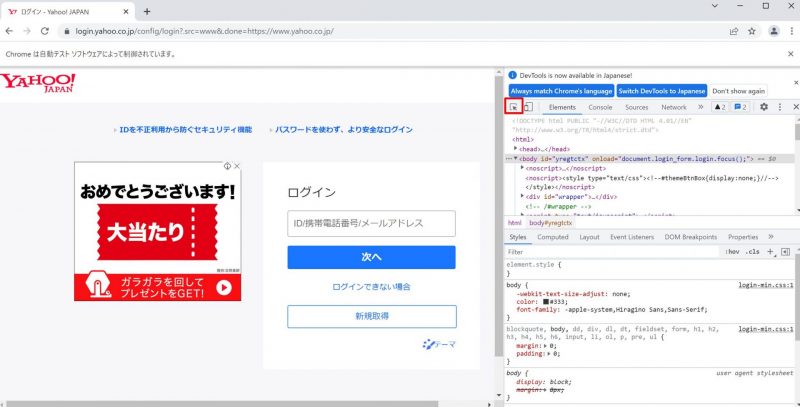
するとサイトの要素を指定できるようになりますのでIDを入力するテキストボックスにカーソルをあわせます。 あわせると、そのオブジェクトの情報が表示されます。

そのままテキストボックスをクリックします。 クリックすると、右の調査用画面が、その対象の要素の部分へ移動します。 今回、クリックしたテキストボックスの要素のidが「username」ということがわかりました。

もう一つ要素の取得として、「次へ」の要素を取得してみます。
先程と同様に、矢印ボタンを押して、「次へ」をクリックします。 すると、 idが「btnNext」であることがわかります。

こうして取得した要素のidを利用して、文字書き込んだり、ボタンをクリックしたりという処理をプログラミングしていきます。
Yahooにログインするコードを書いてみよう
Yahooにログインするには以下のコードでログインできます。
from selenium import webdriver
import time
#■個別設定
#ChromeDriverのPATHを設定する
chromeDriverPath = "C:\chromedriver\chromedriver.exe"
#ログインしたいYahooIDを設定する
yahooID = "あなたのYahooID"
#ログインしたいYahooIDのパスワードの設定
password = "あなたのパスワード"
#要素が見つかるまでの最大待機時間を設定する(20秒)
timeMaxWait = "20"
#chromeを起動する
driver = webdriver.Chrome(executable_path=chromeDriverPath)
#要素が見つかるまで待機する設定
driver.implicitly_wait(timeMaxWait)
# yahooのログイン画面を開く
driver.get("https://login.yahoo.co.jp/config/login?.src=www&.done=https://www.yahoo.co.jp/")
#「ユーザーID」の要素を指定して取得してユーザーIDを入力する
elemUserName = driver.find_element_by_id('username')
elemUserName.send_keys(yahooID)
#「次へ」の要素を取得してクリックする
elemNextbtn = driver.find_element_by_id('btnNext')
elemNextbtn.click()
#「パスワード」の要素を取得してパスワードを入力する
elemPasswd = driver.find_element_by_id('passwd')
elemPasswd.send_keys(password)
#「ログイン」の要素を取得してクリックする
elemSubmit = driver.find_element_by_id('btnSubmit')
elemSubmit.click()
#5秒待機
time.sleep(5)
# ブラウザを終了する。
driver.close()順番に確認していきます。
以下を、ログインしたい自分のYahooID、パスワードに変更して下さい。
#ログインしたいYahooIDを設定する
yahooID = "あなたのYahooID"
#ログインしたいYahooIDのパスワードの設定
password = "あなたのパスワード"要素が見つかるまでの最大時間を設定しています。これを設定しておかないとページの推移時などにエラーになります。
timeMaxWait = "20"「implicitly_wait」を利用することで、要素が見つかるまでの時間処理を待機させます。
driver.implicitly_wait(timeMaxWait)「get」をすることで、指定したリンク先へ移動します。
driver.get("https://login.yahoo.co.jp/config/login?.src=www&.done=https://www.yahoo.co.jp/")「find_element_by_id」で指定したIDの要素を取得します。
elemUserName = driver.find_element_by_id('username')「send_keys」で取得した要素に指定した文字列を書き込みます。
elemUserName.send_keys(yahooID)「click」で取得した要素をクリックします。
elemNextbtn.click()「sleep」で5秒待機します。
time.sleep(5)「close」でブラウザを閉じます。
driver.close()文字認証などの入力が必要な場合は諦めるか、文字認証までを手動で行って、その後の処理を自動化するような仕組みを検討してみましょう!
Xpathからテキスト・リンクアドレス情報を取得してみよう!
先程はIDから要素を取得しましたが、次はXPathというものから要素を取得してみます。
XPathがなにかわからなくても説明通りに進めば大丈夫です。
Yahoo!ニュースの「アクセスランキング」という文字を取得してみます。
まずはChromeでサイトにアクセスします。

「F12」から先程と同じ方法で「アクセスランキング」の要素をクリックします。
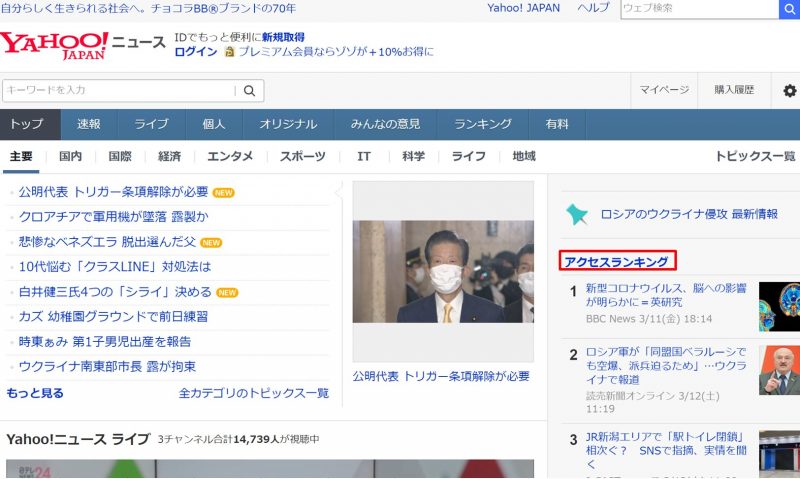
要素をクリックすると、HTML情報がハイライトされます。

これを右クリックして、Copy > 「Copy Xpath」をクリックします。
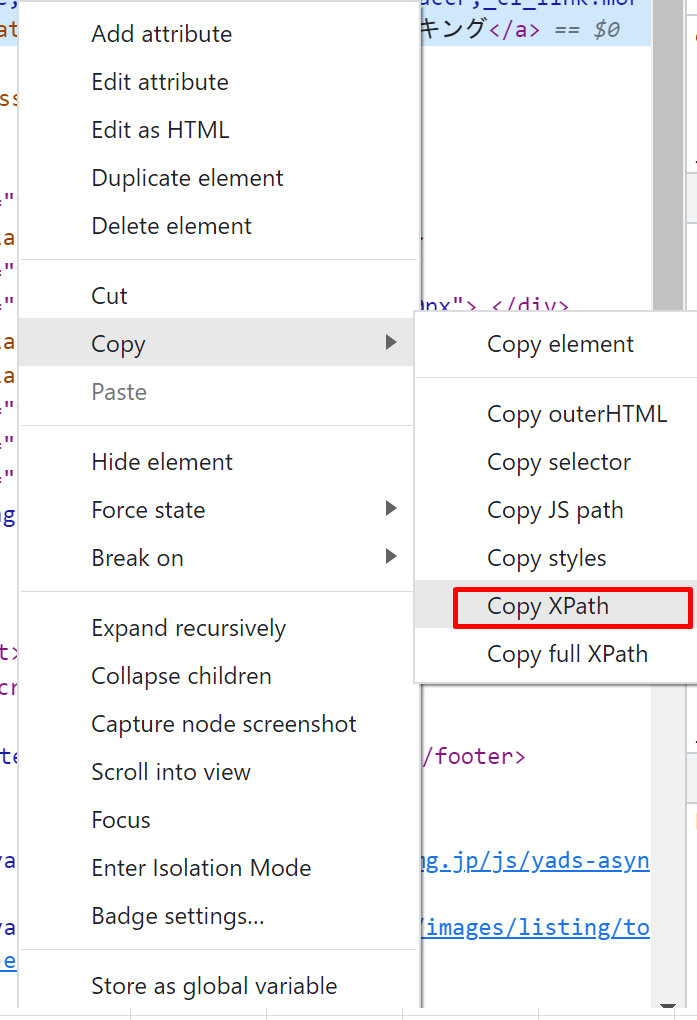
メモ帳などに貼り付けると以下のような情報が取得できていることがわかります。
//*[@id="accr"]/h2/aこれを利用してテキストデータを取得していきます。
XPathを利用してテキスト・リンクアドレス情報を取得するコードを書いてみよう
以下のコードで、XPathから情報を取得することができます。
from selenium import webdriver
import time
#■個別設定
#ChromeDriverのPATHを設定する
chromeDriverPath = "C:\chromedriver\chromedriver.exe"
#要素が見つかるまでの最大待機時間を設定する(20秒)
timeMaxWait = "20"
#chromeを起動する
driver = webdriver.Chrome(executable_path=chromeDriverPath)
#要素が見つかるまで待機する設定
driver.implicitly_wait(timeMaxWait)
# yahooのログイン画面を開く
driver.get("https://news.yahoo.co.jp/")
#XPathで情報を取得する
elemText1 = driver.find_element_by_xpath('//*[@id="accr"]/h2/a')
#取得した要素のテキストを確認する
print(elemText1.text)
#取得した要素のアドレスを確認する
print(elemText1.get_attribute("href"))
順番に確認していきます。
「find_element_by_xpath」を使って上記で取得したXPathから要素を取得しています。
elemText1 = driver.find_element_by_xpath('//*[@id="accr"]/h2/a')「text」を使って要素からテキスト情報を取得しています。
print(elemText1.text)「get_attribute(“href”)」を使って要素からリンク情報を取得しています。
print(elemText1.get_attribute("href"))要素に含まれる複数のテキスト情報を取得してみよう
次は、トップニュースの情報を取得して、そこから各ニュースのテキストを分解して取得してみましょう。
対象要素のXPathをする
先程と同様に要素からXPathの情報を取得します。
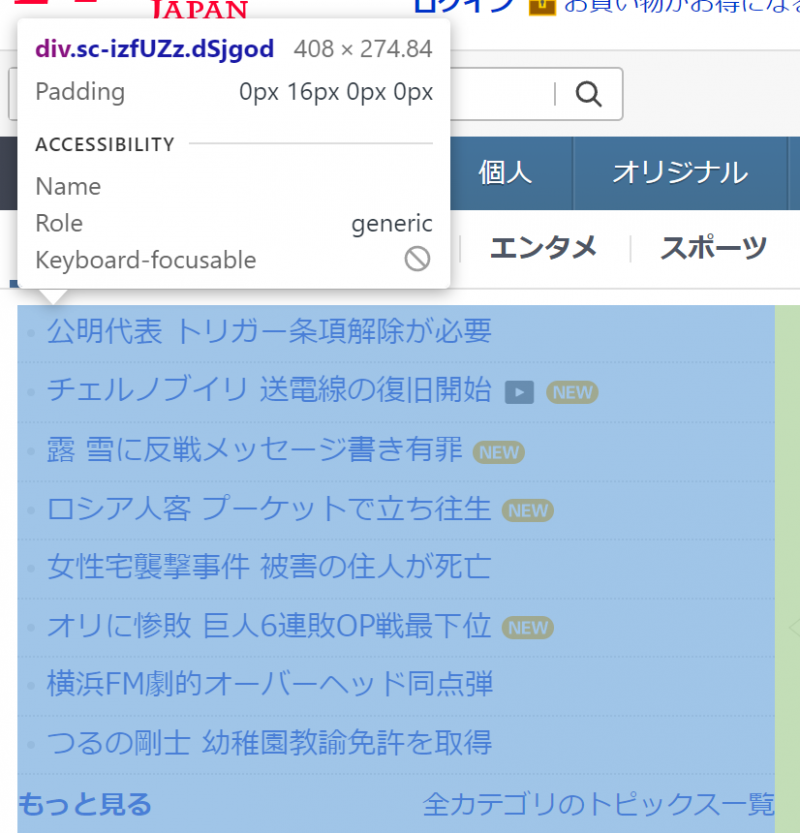
//*[@id="uamods-topics"]/div/div要素に含まれる複数のテキスト情報を取得するコードを書いてみよう!
以下のコードで複数のテキスト情報を取得することができます。
from selenium import webdriver
import time
#■個別設定
#ChromeDriverのPATHを設定する
chromeDriverPath = "C:\chromedriver\chromedriver.exe"
#要素が見つかるまでの最大待機時間を設定する(20秒)
timeMaxWait = "20"
#chromeを起動する
driver = webdriver.Chrome(executable_path=chromeDriverPath)
#要素が見つかるまで待機する設定
driver.implicitly_wait(timeMaxWait)
# yahooのログイン画面を開く
driver.get("https://news.yahoo.co.jp/")
#XPathで情報を取得する
elemNews = driver.find_element_by_xpath('//*[@id="uamods-topics"]/div/div')
#find_elements_by_tag_nameを利用して「li」タグの情報をリスト化する
lstElemLi = elemNews.find_elements_by_tag_name("li")
#リスト化した要素情報のテキストを順番に出力する
for X in lstElemLi :
print(X.text)実行すると以下のようにテキスト情報が出力されました。

順番にコードを説明していきます。
「find_elements_by_tag_name」で取得した要素からさらに「li」のタグ要素のリストを取得しています。今までは「element」でしたが、「elements」とすることで、複数の要素を取得することができます。
lstElemLi = elemNews.find_elements_by_tag_name("li")リストで取得した要素情報のテキストを順番に出力します。
for X in lstElemLi :
print(X.text)まとめ
今回は以下の内容を紹介しました。
- Seleniumでスクレイピングを行うための前準備の方法
- ChromeからHTML要素を取得する方法
- スクレイピングでYahooに自動ログインする方法
- スクレイピングでXPathからテキスト・リンクアドレス情報を取得する方法
- 要素に含まれる複数のテキスト情報を取得する用法
スクレイピングを身につけることでWebから色々な情報を操作・取得することができるようになります。日々の情報収集などを自動で行うことで日々の時間を有効活用できるようになるかもしれません。
本当に色々なことに応用できますので、ぜひチャレンジしてみてください!
今回の記事が、皆さんの技術力向上につながると嬉しいです。
以上、おつかれさまでした!